Building a Reliable LLM-Powered Chinese Idiom Finder
This essay explains my approach to building a Large Language Model (LLM) -powered web app during my 12-week programming retreat at the Recurse Center (RC) in Brooklyn, New York this Fall (2025).
After completing an intensive nine-month Chinese language program at National Taiwan University, I wanted to keep my language skills sharp while learning more about AI engineering. This led me to create “Chinese Idiom Finder”, a LLM-powered web app that helps users understand chéngyǔ (成语), the four-character idioms central to Chinese expression, as well as other common Chinese sayings. A user inputs a description of a situation in English and the app prompts a LLM and then validates the LLM output with trusted sources before returning a relevant Chinese idiom with its definition and contextual explanation.

Running LLM Locally was Too Slow
As this was a personal project, I wanted to see how far I could get without paying for a LLM hosting provider. I tried using Ollama, a free and open source software that allows local LLM deployment and operation. However, due to the storage and memory limits on my computer, I could only run smaller 1-billion-parameter LLMs, which led to poor output accuracy. For example, the LLM would return a Chinese phrase that was not an actual idiom, or something irrelevant to the input situation.
Hugging Face Spaces: Making use of Gradio and Cerebras AI
Next, I migrated my project to Hugging Face (HF) Spaces, which provides a platform to host my web app, a seamless integration with Gradio (a frontend framework for ML/ AI projects), and more powerful LLMs. However, these larger models still took a long time to return output for the prompt, which looks something like this:
Given a situation, respond with exactly:
1. A Chinese idiom (includes 成語、俗語、諺語),
written in simplified Chinese characters,
that conveys the idea of the given situation.
2. Its literal English translation
3. Explain idiom in English.
Keep explanation to 2-3 concise sentences.
While the idiom output returned by higher-parameter LLM was more accurate, the response time took up to 30 seconds. To improve the performance, I switched to calling Cerebras, an AI inference provider, that is offered on the HF Spaces platform. However, the monthly inference limit on HF is very low. After some research, I switched directly calling Cerebras AI, which has a Personal Tier with inference rate limits sufficient for an app with about a dozen active users. Switching to Cerebras improved performance significantly - average response time is closer to 1-5 seconds. On Cerebras’s Personal Tier, I have access to Openai’s “gpt-oss-120b”, which is trained on English and Chinese language data. After some manual testing, I found that this model provides accurate enough idiom responses.
LLM Output Multi-layer Verification
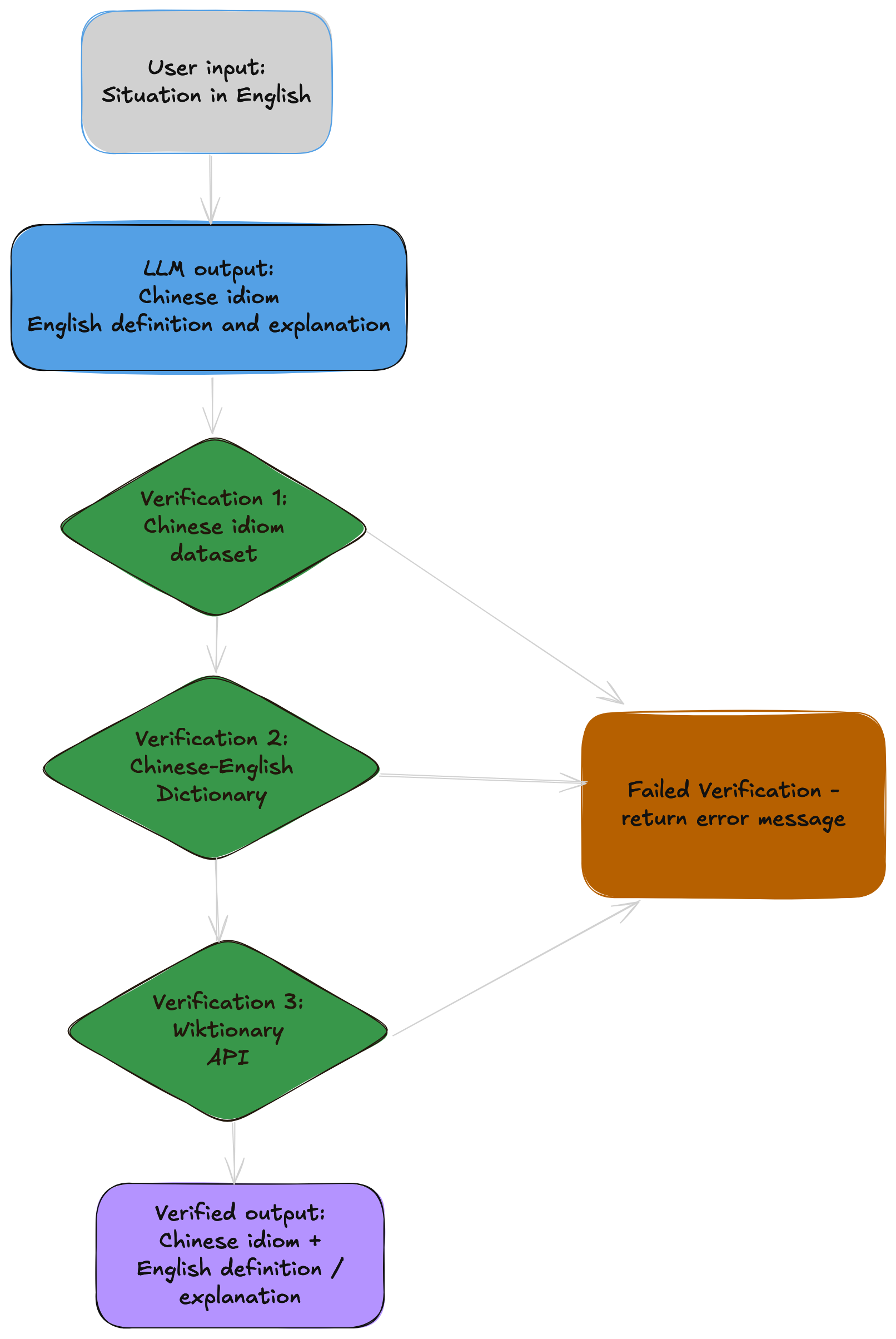
No matter the size of a LLM, it can still produce incorrect results. That’s why I implemented a multi-layered validation system to verify its output. After the LLM returns a Chinese idiom, it is first validated against a curated published dataset of 4,000 verified idioms. If no match is found, the system falls back to checking a Chinese English dictionary (CC-EDICT). If this check also fails, the final check is a call to the Wiktionary API. If there is no Wiktionary data for the idiom returned by the LLM, then I return a message saying “No verified idiom found for this situation.” This hybrid approach combines the LLM's contextual understanding with the reliability of multiple reference data sources, effectively eliminating hallucinations from being returned to the user.
Other Improvements
To further improve performance, I implemented session-level caching, so repeated input queries reuse previously verified outputs without re-calling the LLM. This made the app faster (average response decreased from 30 seconds to 2 seconds), more cost-efficient (no need to pay for premium monthly inference calls), and more reproducible (same idiom output for same situation in a given session). Moreover I used a well-known Python pinyin library to produce the pinyin pronunciation for the Chinese idiom output, rather than prompting the LLM for the pinyin, which could be another source of inaccuracy.
Retrospective
“Chinese Idiom Finder” was most recently shared at a demo event at RC in mid-October, where close to 30 users came by to use my app. I also shared the app with about a dozen sample users for more detailed testing and feedback. This project taught me that reliable LLM applications often require hybrid approaches - combining model creativity with structured verification. Moreover, caching can dramatically improve both user experience and reduce AI inference calls. These lessons in iterative development and LLM output verification are directly applicable to building robust ML platforms and production systems.